お久しぶりです。ゆきとです。
今日はプログラムを書かずにOCR(光学的文字認識)を行うやり方について紹介をしていきます!
やり方を紹介する前に、まずOCRについて簡単な説明をすると、OCRとは「手書きの文字や写真内の文字を、自動で認識してくれる技術」のことです。
抽象的でわからないなと感じている方もいると思いますが、手を動かしていく中で理解できると思いますので、とりあえず「そんなもんなんだなー」っと思っていただければ幸いです。
それでは早速プログラムを書かずにOCRをしていきましょう!
プログラムを書かずにOCR
今回プログラムを書かずにOCRをするために「Nanonets」というサービスを使います。まず、Nanonetsの概要を紹介し、その後OCRを行うための手順を紹介していきます。
Nanonetsとは
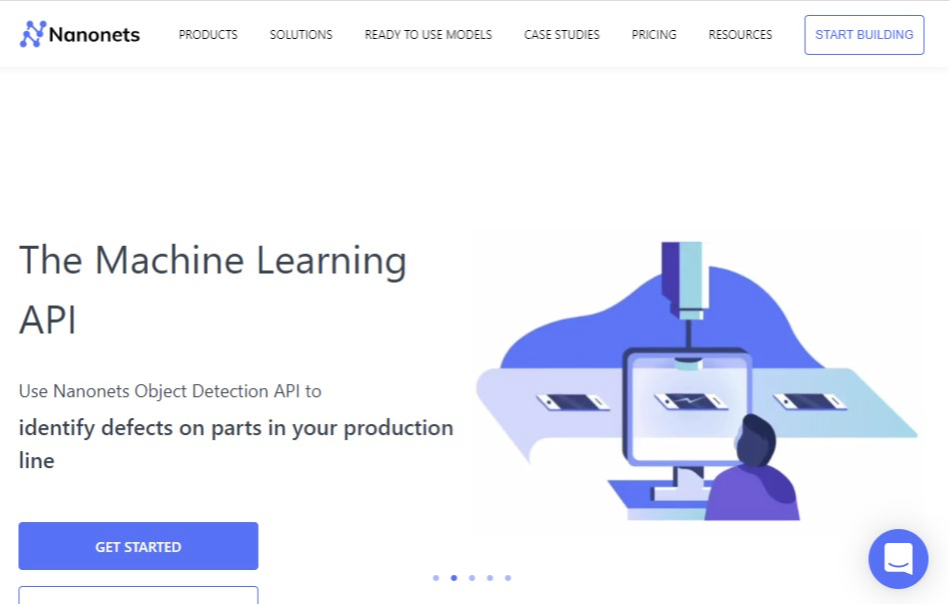
画像認識に特化したGUIサービス(https://nanonets.com/ )
ほかのGUIサービスのWatsonと比べるとUIが分かりやすく、Google検索結果から自動で学習画像を取り込んでくれる機能など、特にマニュアルを読んだりしなくても簡単に使いこなすことができるツール
マーカー線の部分の特徴から今回はNanonetsを使用しています。
お待たせしました!それでは実際にOCRを行っていきましょう!
OCRを行うための手順
手順1 : ログイン
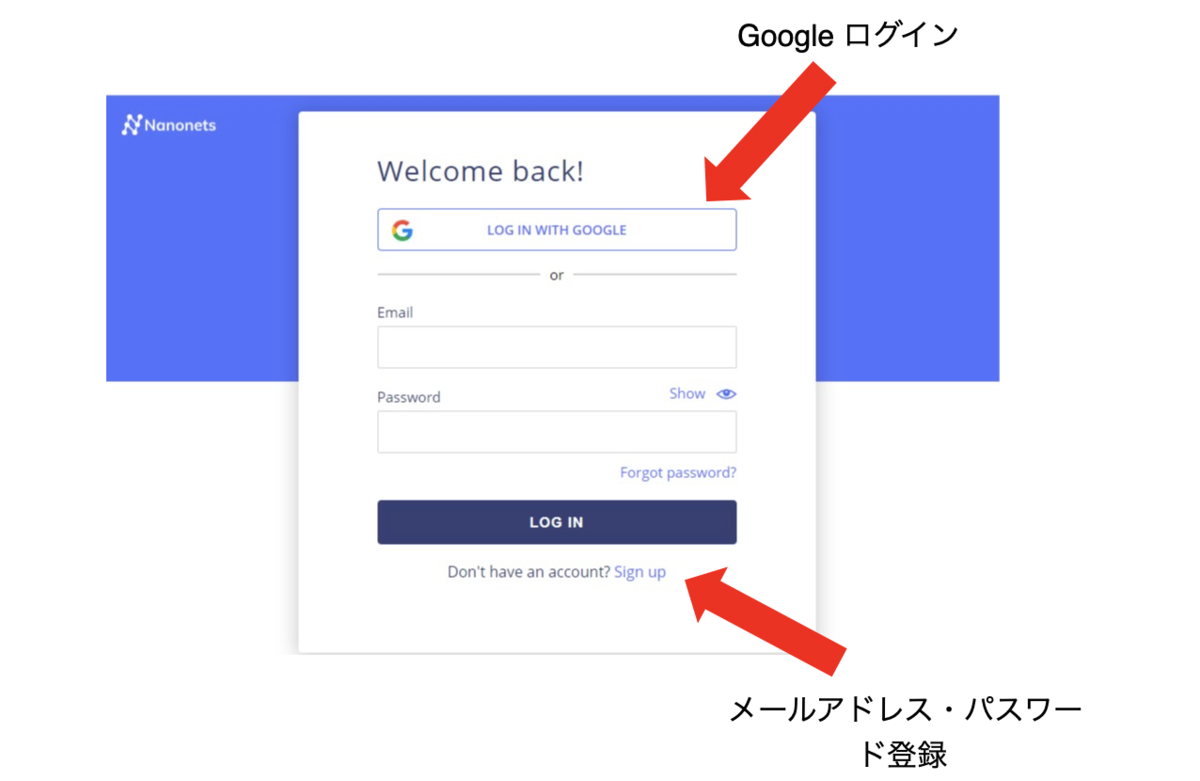
初期画面の「GET STARTED」から下記のログイン画面に飛び、googleアカウント持っている人はgoogleアカウントでログインし、手順3へ。Googleアカウントを持っていない人はログイン画面の下の方にあるSign upからメールアドレスとパスワードを登録するために手順2へ。
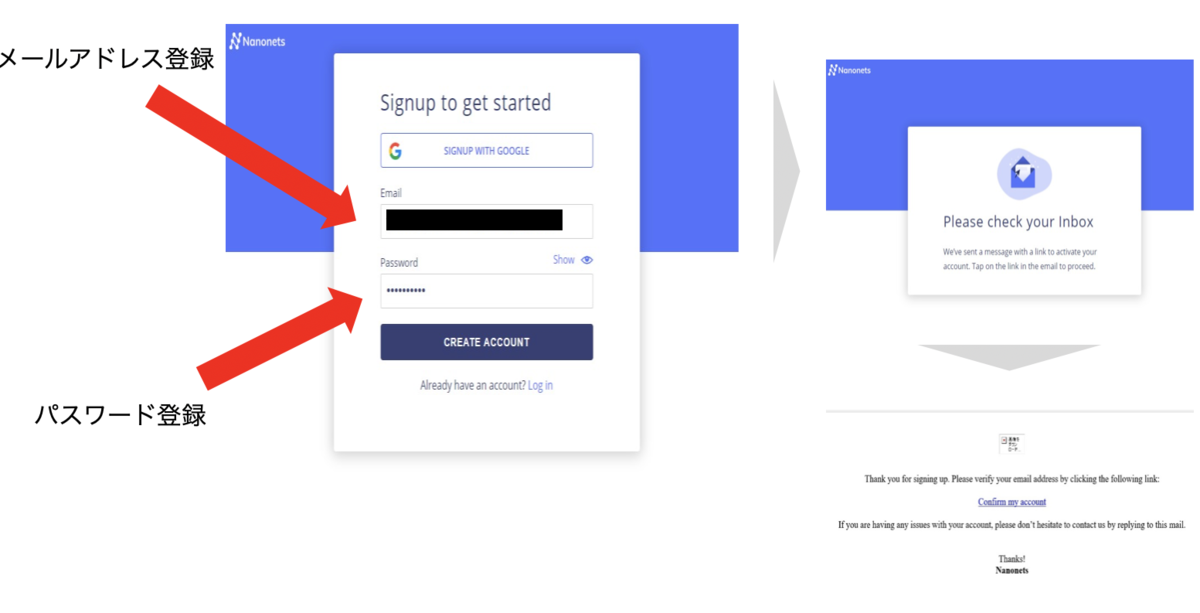
手順2 : アカウント登録
ログイン画面から登録したいメールアドレス、パスワードを入力しアカウントを作成。登録したメールアドレスにNanonetsからメールが届くので、メールを開き「Comfirm my account」をクリックする。
手順3 : OCRを選択
Nanonetsにログインが完了すると下記左側の画面のようなホームページが出てくるので、その中のCreate your own OCR Modelを選択、その後右側画面が出現する

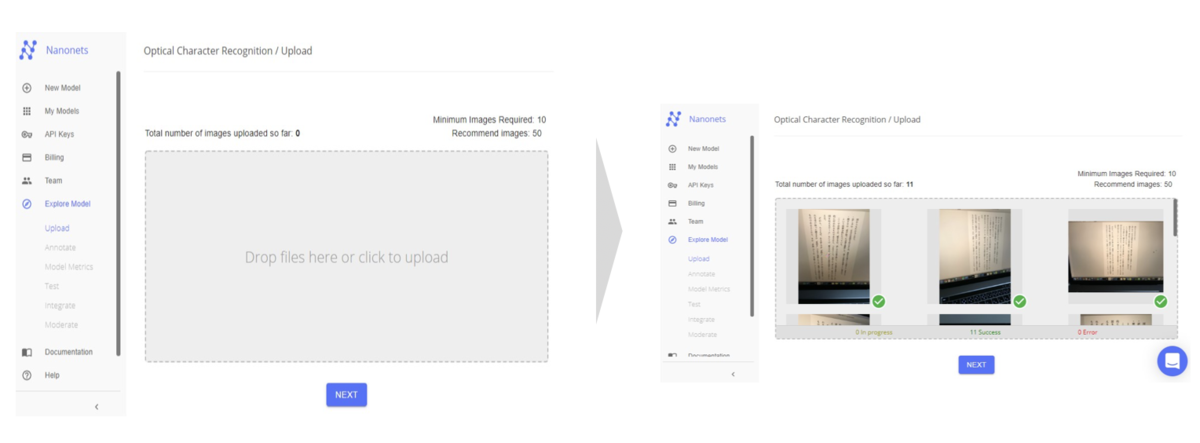
手順4 : 訓練データをアップロード
githubにあるNanonets_OCR_Train_Photo(
)をフォルダごとダウンロードし、下記の左側の画面にファイルのみをすべてアップロードすると、右側の画面のようになるので、NEXTをクリック
*フォルダを画面にアップロードしないこと
*写真の順番は人によって異なる可能性があるので、気にせず進める
手順5 : LABELを設定
下記左側画面の赤枠の部分の「+ ADD LABEL」をクリックし、好きなLABEL名をつけSAVEをクリック
*LABELとは、学習させるデータが正解の集まりであると機械に認識させるためのもの
*LABEL名が思いつかない人は、test_ocr等にするとよい
*写真の枚数が11枚になってますが、これは私が誤って追加してしまったものなので、みなさんの画面の写真枚数とは違いますが、気にしないでください!

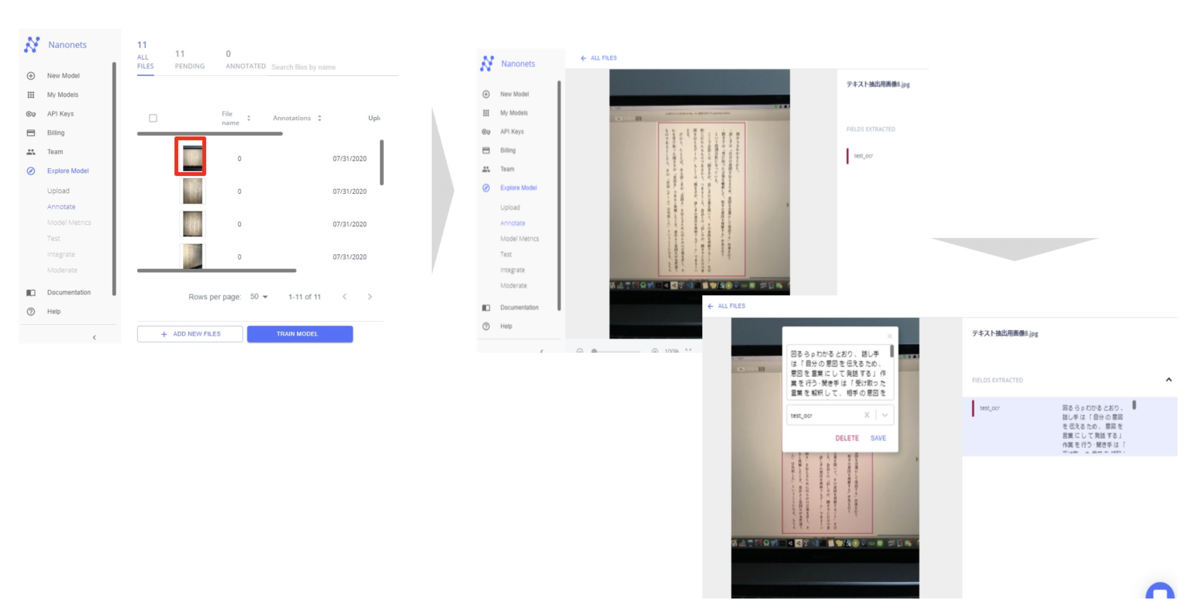
手順6 : アノテーション処理
手順5でLABEL名を設定した後、アノテーション処理を行う
*アノテーション : テキストなどのデータにタグをつける作業のこと
*アノテーション処理 :ファイルの画像の部分(赤枠)をクリックすると、右側の画面のような場所に飛ぶので、文章が表示されている部分だけを範囲選択(マウス左クリックしながら移動)したのち、右側下画面のような記載が出てくるので何もせずSAVEを選択
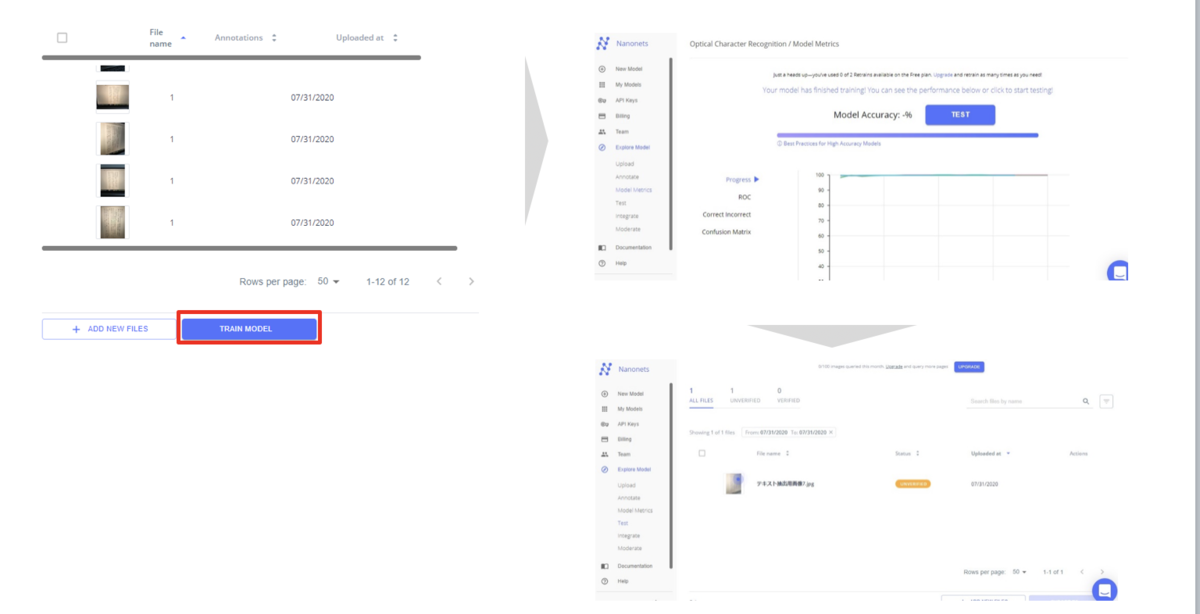
手順7 : 学習
手順6のアノテーションをアップロードしたすべてのファイルに行いTRAIN MODELボタンをクリックすると、右側画面のようにMODELが作られるので少し待機(1分~2分)するとTESTボタンがクリックできるようになるため、クリック。githubのNanonets_OCR_Test_Photo(
Nanonets_data_folder/Nanonets_OCR_Test_Photo at master · yukiyukiponsu/Nanonets_data_folder · GitHub
)をダウンロードし、中にある1ファイルを右下のような形でアップロードする。
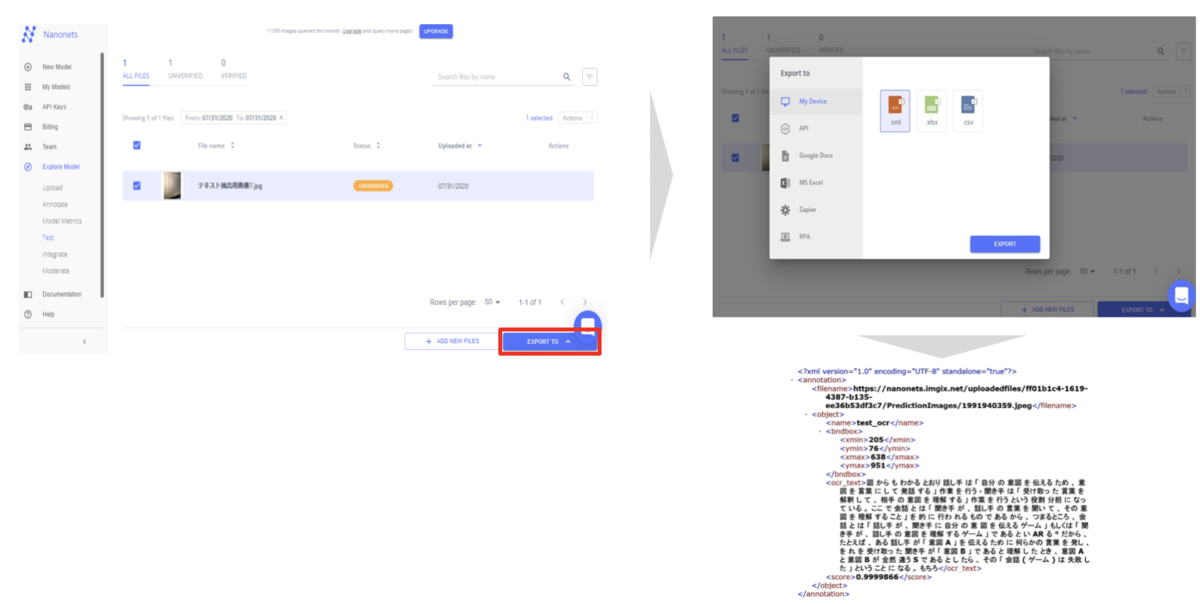
手順8 : OCRの結果
手順7でアップロードしたファイルにチェックを入れ、EXPORT TO(赤枠)をクリックし、xmlで保存。Zipファイルが自動でダウンロードされるので、それを解凍し中にあるファイルを開くと、右下画面のような結果が出てくる。右下画面の結果が、10枚の写真を学習させたモデルに、新しい写真を入れた時の読み取り予想テキストとなっている。
以上です!!
なんとOCRが8つの手順で、できてしまいました。
プログラムを書かなくてもOCRができるようになっただなんて...
便利な世の中になりましたね...驚きです。
今日もブログを読んでくださり誠にありがとうございました!
このような記事をこれからもどんどん書いていこうと考えているので、少しでも良かったと思う人は読者登録をしていただけると泣いて喜びます!
あとさりげなくスターを送ってもらえると記事作成のモチベーションに繋がるので、帰り際にポチッとお願いします!!
今日は本当にありがとうございました!それではまた後日!!